.png)
コンテナの解剖学 101: クラスターとは
ネットワークの観点から見ると、コンテナはネットワークの「エッジ」(ネットワーク転送の決定とパケットが最終宛先に到達するまでの境界)をホストの奥深くまで広げます。エッジはもはやホストのネットワークインターフェースではなく、ホスト内の論理構造の何層にも重なっています。そして、ネットワーク・トポロジーは抽象化され、オーバーレイ・ネットワーク・トンネリング、仮想インターフェース、NAT 境界、ロード・バランサー、ネットワーク・プラグインという形で、ホスト内のこれらの論理構成に深く入り込んでいます。ネットワークとセキュリティのアーキテクトは、アーキテクチャを設計する際に OS の内部構造を無視できなくなりました。コンテナは、パケットがホストの NIC を通過したあと、パケットの行き先をこれらのアーキテクチャに強制します。
オーケストレーションシステム
とはいえ、コンテナ環境に何らかの秩序をもたらすには、オーケストレーションシステムが必要です。オーケストレーションシステムは、コンテナの整理、スケーリング、自動化に関する詳細を管理し、コンテナの動作に関連するさまざまなコンポーネントを中心に論理構造を作成します。また、コンテナのランタイムに関連する論理的な境界を整理し、IP アドレスを割り当てることができる論理構造を作成する役割も果たします。とはいえ、このようなシステムは外部にあるため、特定のコンテナ・ランタイム・インスタンスのライフサイクルを実際にデプロイして管理することはできません。これらのインスタンスは、たとえばまだ Docker によって処理されています。
コンテナオーケストレーションシステムは多数ありますが、現在最も一般的に使用されているのは 2 つです。 クベルネテス そして オープンシフト。どちらも同じ基本目標を達成していますが、主な違いは一方はプロジェクトで、もう一方は製品であるということです。Kubernetes は主に Google から生まれたプロジェクトであり、OpenShift は Red Hat が所有する製品です。一般的に言えば、Kubernetes はパブリッククラウド環境で最も多く、OpenShift はオンプレミスのデータセンターで最もよく見られますが、両者の間にはかなりの重複があります。要するに、Kubernetes は両方のアプローチの基礎となっていますが、それぞれの用語の違いはわずかです。
コンテナの簡単な歴史
信じられないかもしれませんが、コンテナはKubernetesよりも前のものです。たとえば、Docker は 2013 年に初めてコンテナプラットフォームをリリースしましたが、Kubernetes はパブリッククラウドに焦点を当てたプロジェクトをリリースしたのは2014 年になってからです。OpenShift はその両方よりも前に立ち上げられ、オンプレミスのデータセンターにデプロイされたホストに重点が置かれていました。
ランタイムは「ローカルホスト」と固有のポートを介して相互に通信できるため、コンテナランタイムをローカルホストにデプロイするだけで、通常は開発者のニーズを満たすことができます。コンテナランタイムには特定の IP アドレスは割り当てられません。高速で効率的なコードを書き、関連するコンテナーランタイムのコレクション全体にアプリケーションをデプロイすることに重点を置いている場合は、このアプローチで十分です。ただし、そのアプリケーションにローカルホスト外の外部リソースにアクセスさせたい場合や、外部クライアントにそのアプリケーションにアクセスさせたい場合は、ネットワークの詳細を無視することはできません。これが、オーケストレーションシステムが必要な理由の 1 つです。
Kubernetes は、コンテナランタイムの動作を整理するための一連のビルディングブロックと API 主導のワークフローを中心に作成されました。このアプローチでは、Kubernetes は特定のコンテナ環境に関連するホスト内およびホスト間で一連の論理構造を作成し、これらの構造を指すまったく新しいボキャブラリーを作成します。Kubernetes は、これらのビルディングブロックと API 主導のワークフローを、CPU 割り当て、メモリ要件、およびストレージ、認証、計測などの他の指標に関連する一連のコンピューティング指標に適用しますが、セキュリティとネットワークの専門家の多くは 1 つのことに重点を置いています。
IP アドレスが割り当てられた論理構成体に向かう途中で、IP パケットはどの境界を通過するのでしょうか。
ネットワークの観点から見ると、Kubernetes と OpenShift はどちらも、各システム間で語彙がわずかに異なるだけで、論理的で関連性のある構成を階層的なアプローチで作成しています。これを下図に示します。
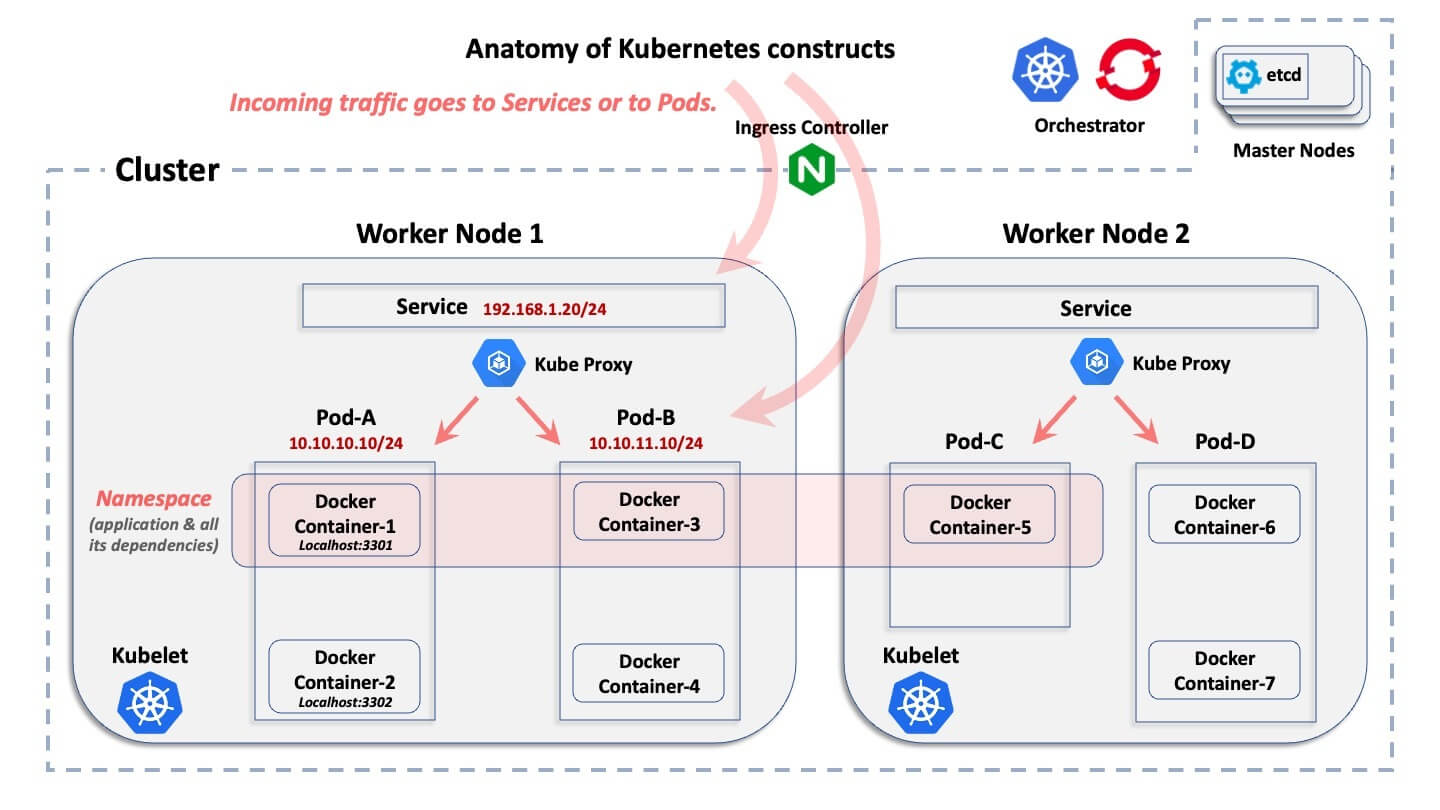
コンテナクラスタのABC
この図は、Kubernetes 環境の基本的な論理構造を示しています。各構成が何をするのかは説明していませんが、互いに論理的に関連していることだけが説明されています。
最も広い構成から最小の構成まで、以下に簡単な説明を示します。
- クラスタ: クラスターは、特定のコンテナ化されたデプロイメントに関連するホストの集まりです。
- ノード: クラスタの内部にはノードがあります。ノードはコンテナが置かれているホストです。ホストは物理コンピューターでも VM でもよく、オンプレミスのデータセンターにもパブリッククラウドにも配置できます。一般に、クラスター内のノードには「マスターノード」と「ワーカーノード」の 2 つのカテゴリがあります。簡単に言うと、マスターノードはクラスターの中央データベースと API サーバーを提供するコントロールプレーンです。ワーカーノードは実際のアプリケーションポッドを実行するマシンです。
- ポッド: 各ノードの内部で、Kubernetes と OpenShift の両方がポッドを作成します。各ポッドには 1 つ以上のコンテナランタイムが含まれ、オーケストレーションシステムによって管理されます。ポッドには Kubernetes と OpenShift によって IP アドレスが割り当てられます。
- コンテナ: ポッドの内部はコンテナランタイムが存在する場所です。特定のポッド内のコンテナはすべてそのポッドと同じ IP アドレスを共有し、固有のポートを使用して Localhost 経由で相互に通信します。
- 名前空間: 特定のアプリケーションをクラスタ内の複数のノードに「水平に」デプロイし、リソースと権限を割り当てるための論理的な境界を定義します。ポッド (したがってコンテナ) とサービスだけでなく、ロール、シークレット、その他多くの論理構造も名前空間に属します。OpenShift ではこれをプロジェクトと呼んでいますが、概念は同じです。一般的に言えば、名前空間は特定のアプリケーションにマップされ、その中のすべての関連コンテナにデプロイされます。名前空間はネットワークやセキュリティーの構成とは関係ありません (Linux の IP 名前空間とは異なります)。
- サービス: ポッドは一時的なもので、突然消えて後で動的に再デプロイされることがあるため、サービスは「フロントエンド」であり、関連するポッドのセットの前にデプロイされ、ポッドが消えても消えない VIP を備えたロードバランサーのように機能します。サービスは独自の IP アドレスを持つ非エフェメラルな論理構造です。Kubernetes と OpenShift のいくつかの例外を除いて、外部接続はサービスの IP アドレスを指し、「バックエンド」ポッドに転送されます。
- クベルネテス API サーバー: ここで API ワークフローが一元化され、Kubernetes がこれらすべての論理構成の作成とライフサイクルを管理します。
コンテナのセキュリティ上の課題
ワークロードの境界に沿ってセキュリティセグメントを作成するには、Kubernetes によって作成されたこれらの基本的な論理構造を理解する必要があります。ホストされたアプリケーションに出入りする外部ネットワークトラフィックは、通常、基盤となるホストであるノードの IP アドレスを指すことはありません。代わりに、ネットワークトラフィックはそのホスト内のサービスまたは Pod のどちらかを指します。そのため、ワークロードに関連するサービスとポッドを十分に理解しておく必要があります。 効果的なセグメンテーションセキュリティアーキテクチャ。
もっと興味がありますか? チェックアウト コンテナセグメンテーションへのネットワークベースのアプローチの課題と、ホストベースのセグメンテーションを使用してそれらを克服する方法に関する論文。


